InitialGPT
Introduction
Inspired by the success of language models in text generation, we propose a data generation tool, InitialGPT, based on the RM2PT requirements prototyping tool and large language models, designed to automatically generate initial data for prototypes to support rapid requirements validation. This tool leverages requirement models and user interactions as inputs, utilizing prompt templates to automatically generate the initial data, followed by post-processing to clean the data, thereby enabling automated generation of initial data.
The demo video and introduction video are described below.
InitialGPT code is found at github.
We have integrated the InitialGPT installation of this tool on RM2PT, you can click here to download.
Background
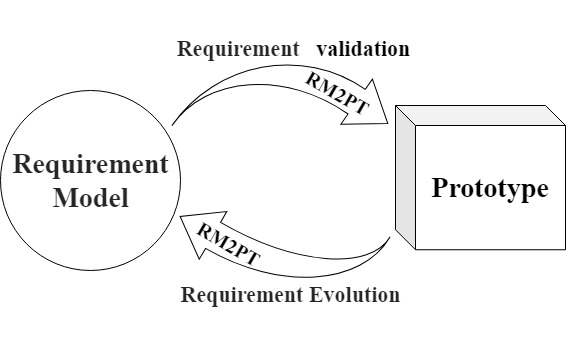
RM2PT (ICSE’19, ICSE’22, ICSE’23,ICSE’24) : The CASE tool RM2PT, which can generate prototypes from requirements models automatically to support requirements validation and evolution.
InputGen (ICSE’23, ICSE’24) : The CASE tool InputGen, which extends and enhances the prototypes generated by RM2PT. It automates the generation of prototype inputs to improve the efficiency of requirements validation.
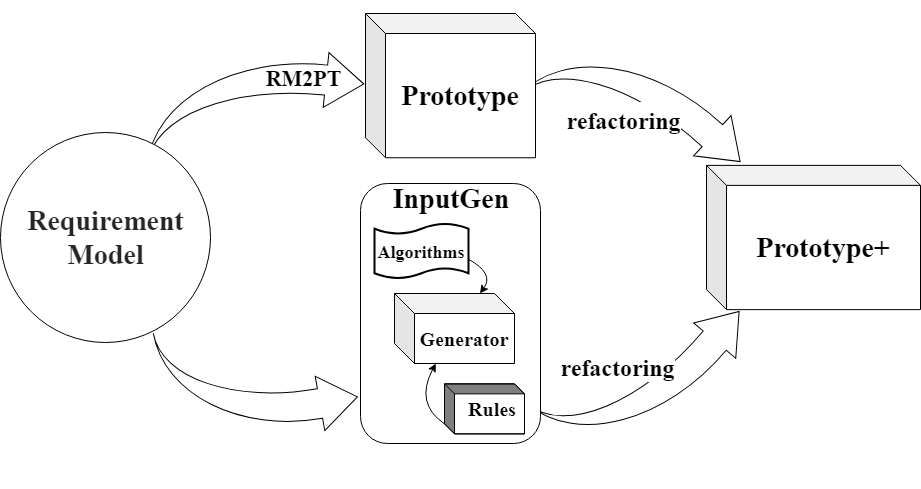
InitialGPT is a tool that extends the functionality of RM2PT and InputGen.
Motivation
**The video cast its motivation is listed as follows (Youtube): **
InitialGPT’s tool demo features as shown below (Youtube):
InitialGPT
InitialGPT is a data generation tool based on the RM2PT requirements prototyping tool and large language models aimed at automating the generation of initial data for prototypes to support rapid requirements validation.
Features
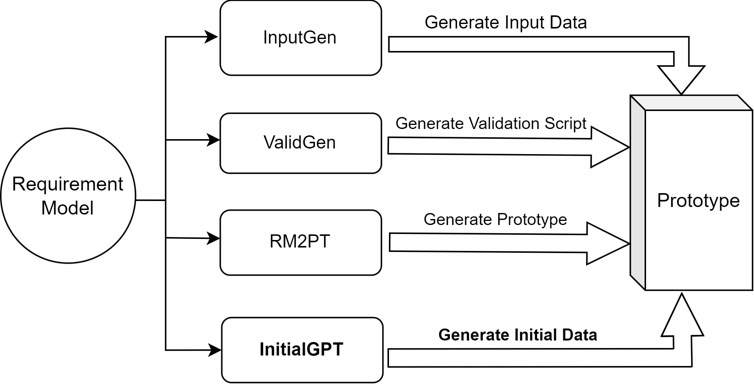
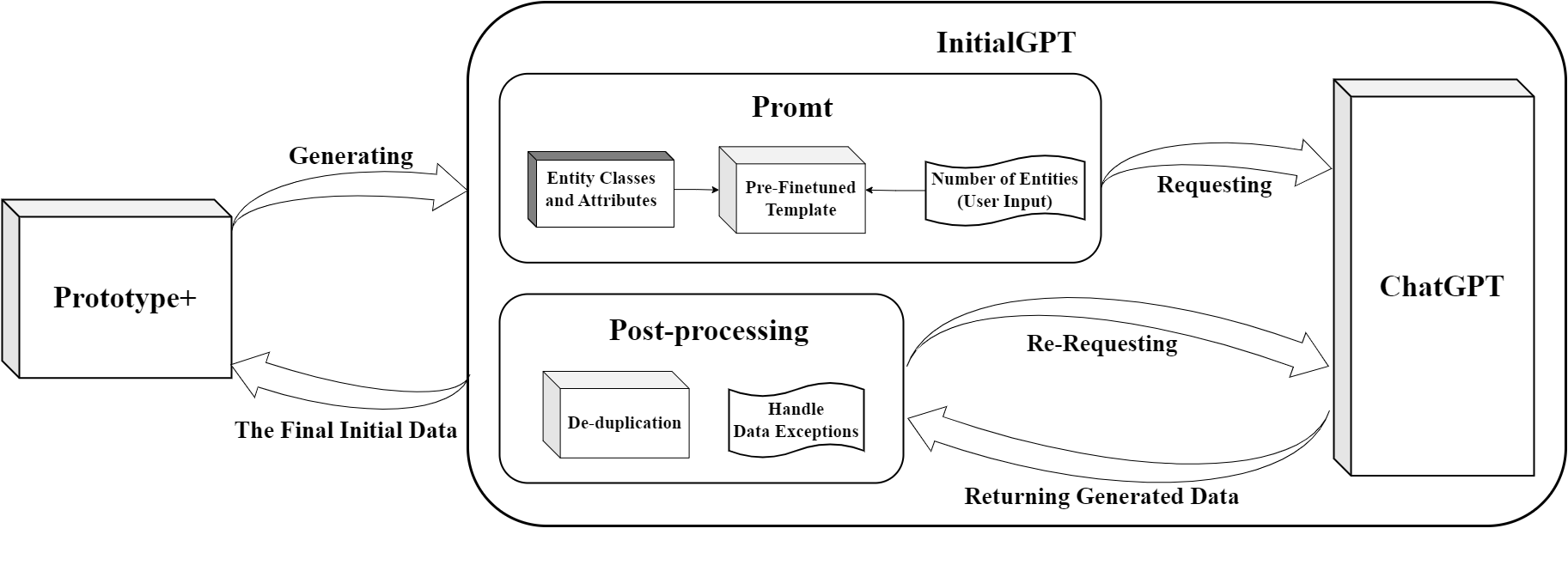
Automatic generation of prompt templates: On the one hand, InitialGPT extracts domain conceptual information from the requirement model, on the other hand, the tool automatically generates requirement information through interaction with the user, and finally generates prompt templates by combining other pre-processed information.
Automatic data generation and post-processing: We design a method to cope with the limitations of api request length and request number of LLMs, and perform data cleansing and re-generation by setting up post-processing rules to ensure that a large amount of reasonable initial data is generated without duplication.
Data Evaluation: We propose a set of initial data generation evaluation metrics oriented to requirements validation to ensure data quality.
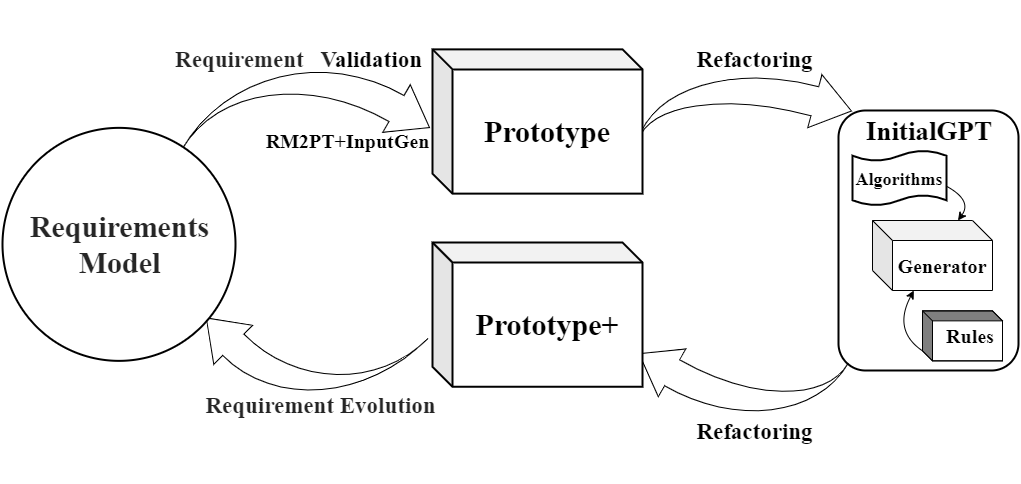
The workflow of InitialGPT is shown in Fig:
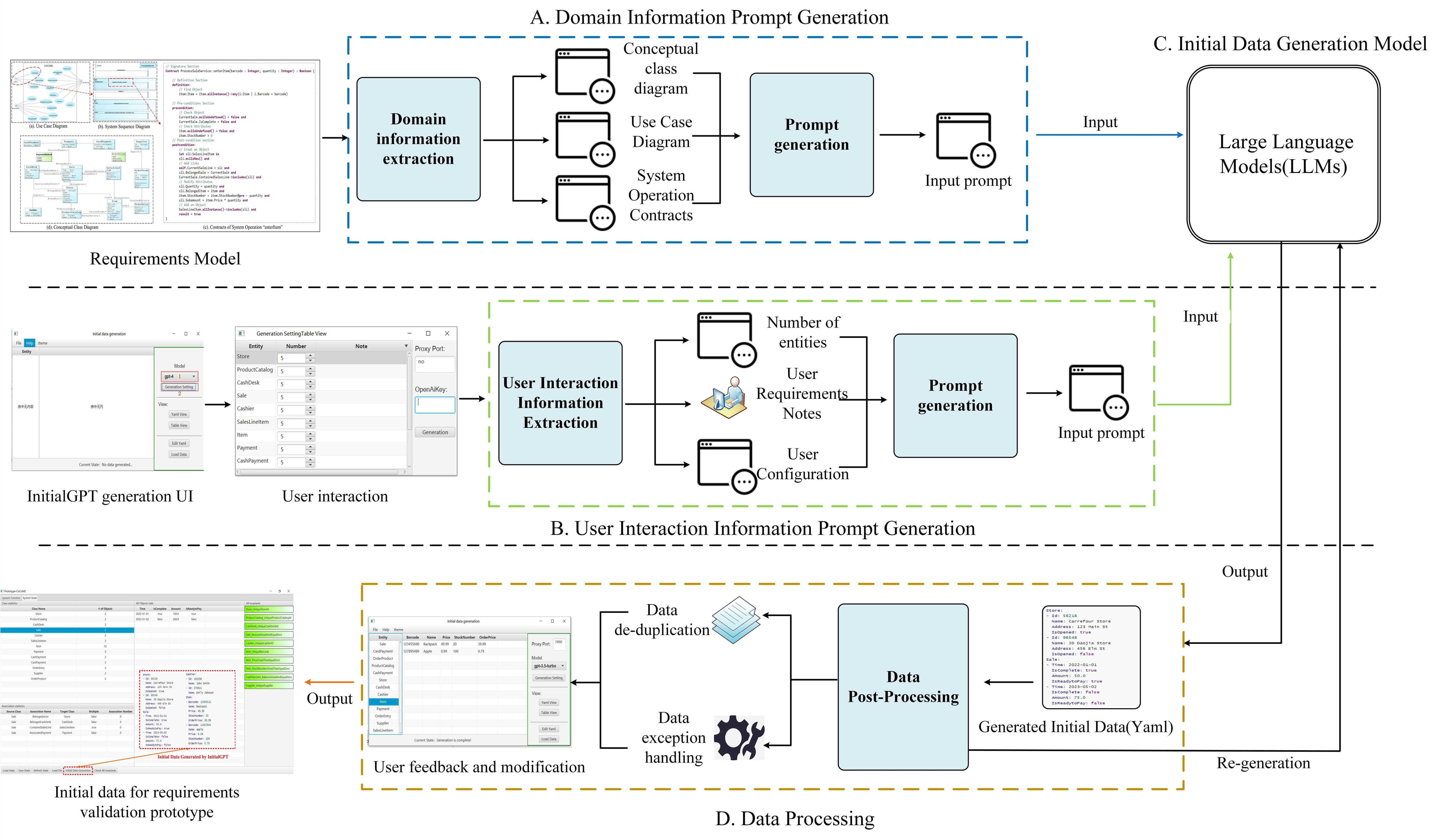
An overview figure of InitialGPT is shown in Fig:
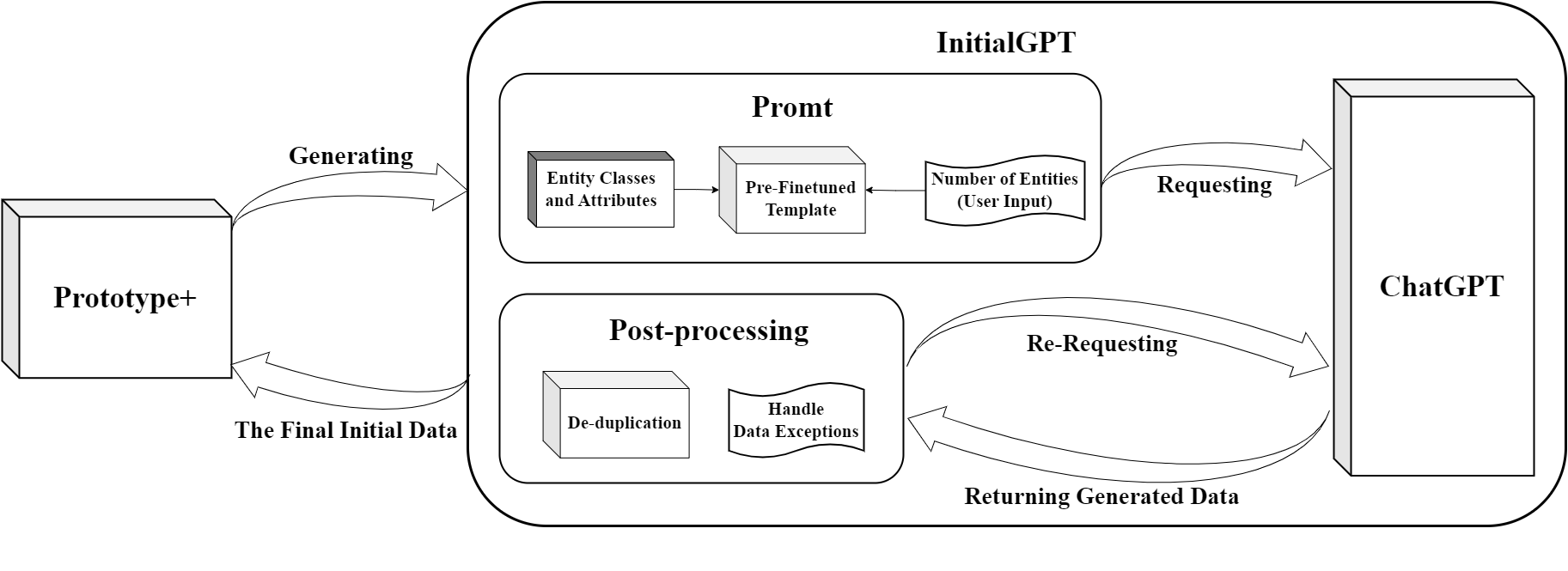
InitialGPT Installation
RM2PT with Integration of InitialGPT tool
We have integrated the InitialGPT installation of this tool on RM2PT, you can click here to download and use it without installing the step by step process below.
Prequest
InitialGPT is an advanced feature of RM2PT. We recommend you to use InitialGPT in RM2PT. If you don’t have RM2PT, download here.
Installation
Here is the step-by-step installation. Click here to download InitialGPT. Follow the steps below to install.
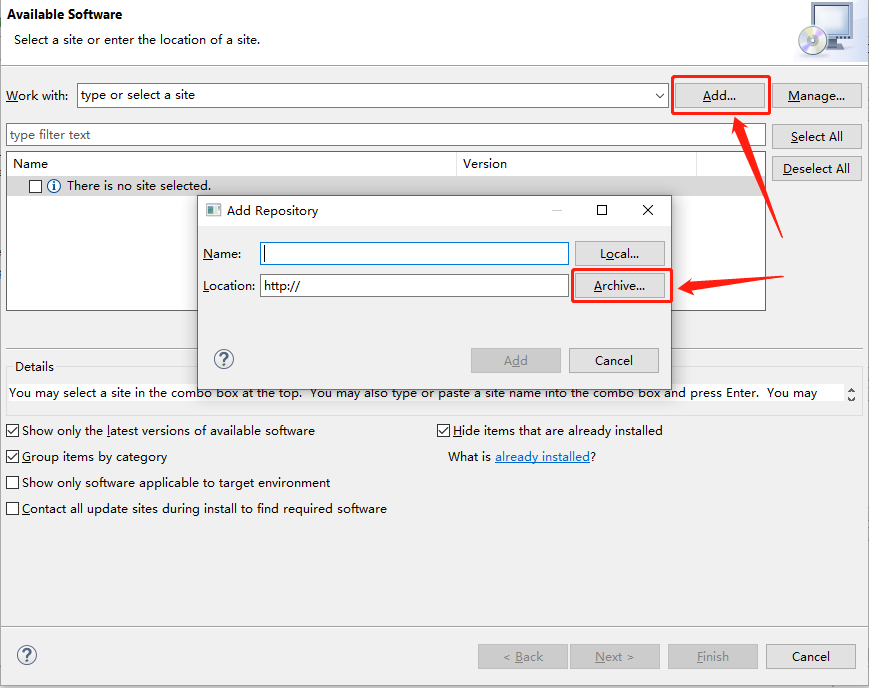
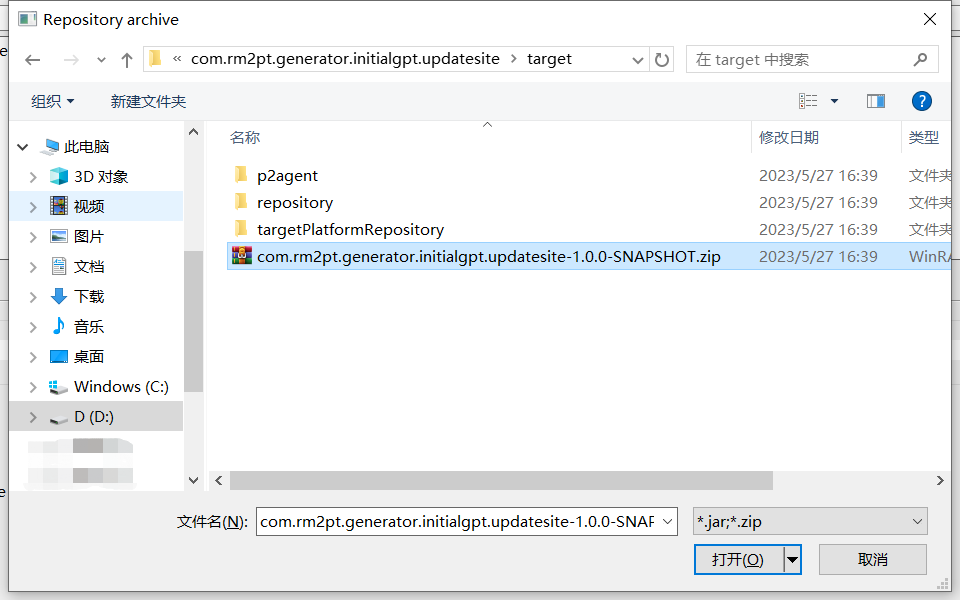
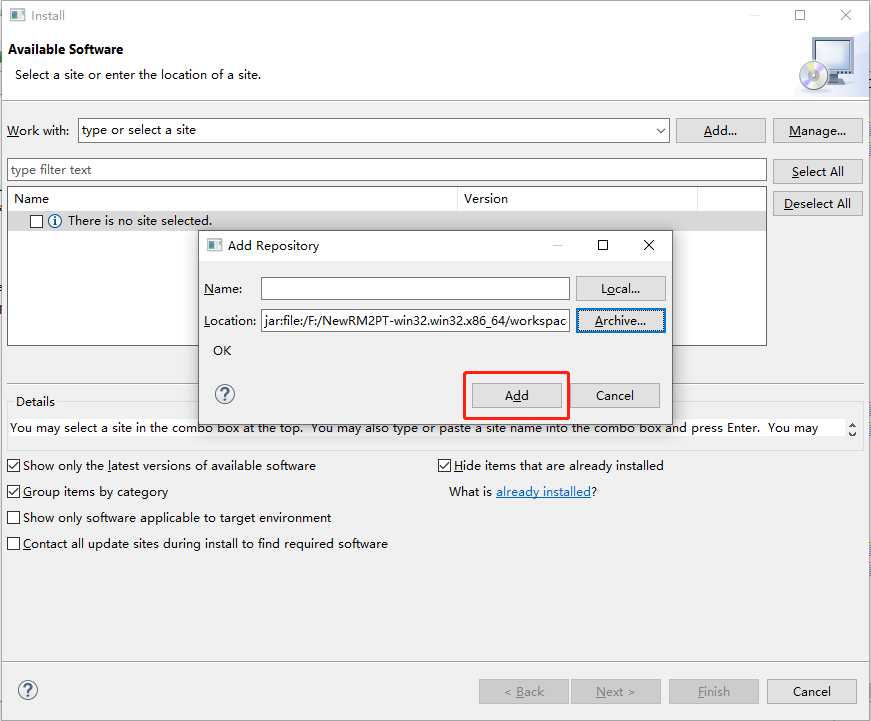
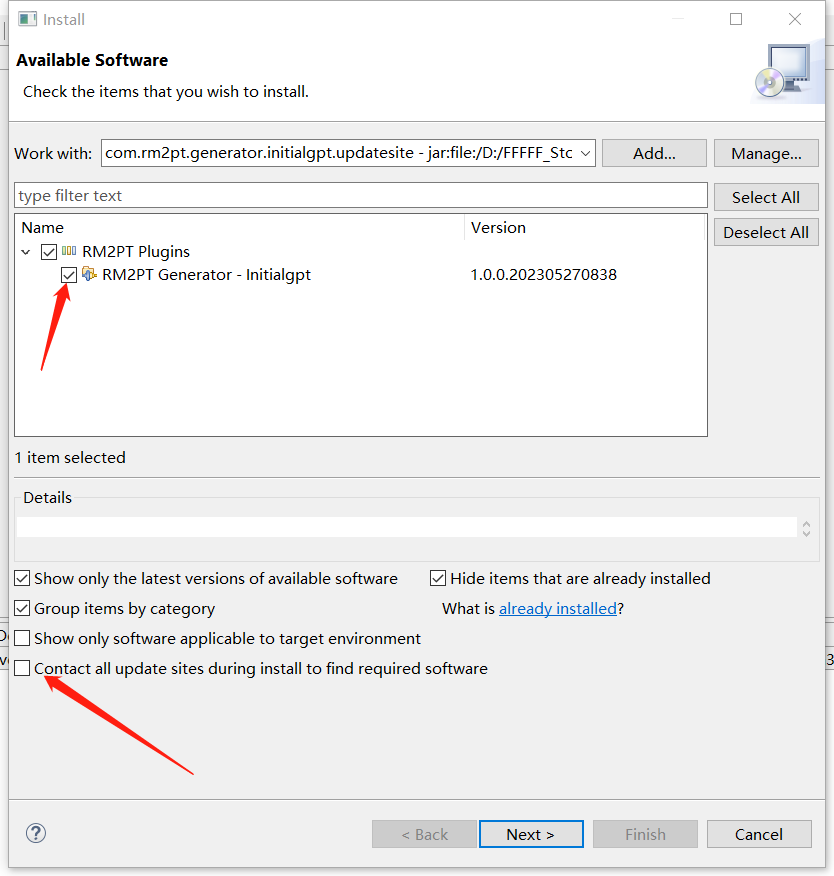
InitialGPT Tutorial
You can view the demo video before installing(in the motivation section).
Prerequest
In order to generate the prototype initial data, you need a requirement model, the RM2PT project. For creating or importing a RM2PT project,you can see the tutorial here. We recommend importing RM2PT projects from Git, which is avaliable at CaseStudies.
Input of InitialGPT — Requirements Model
The input to InitialGPT is a UML requirements model with OCL constraints. The model includes: a conceptual class diagram, a use case diagram, system sequence diagrams, contracts of and system operations.
-
A conceptual class diagram: A conceptual class diagram is a concept-relation model, which illustrates abstract and meaningful concepts and their relations in the problem domain, in which the concepts are specified as classes, the relations of the concepts are specified as the associations between the classes, and the properties of the concepts are specified as the attributes of the classes.
-
A use case diagram: A use case diagram captures domain processes as use cases in terms of interactions between the system and its users. It contains a set of use cases for a system, actors represented a type of users of the system or external systems that the system interacts with, the relations between the actors and these use cases, and relations among use cases.
-
System sequence diagrams: A system sequence diagram describes a particular domain process of a use case. It contains the actors that interact with the system, the system and the system events that the actors generate, their order, and inter-system events. Compared with the sequence diagram in design models, a system sequence diagram treats all systems as a black box and contains system events across the system boundary between actors and systems without object lifelines and internal interactions between objects.
-
Contracts of system operations: The contract of a system operation specifies the conditions that the state of the system is assumed to satisfy before the execution of the system operation, called the pre-condition and the conditions that the system state is required to satisfy after the execution (if it terminated), called the post-condition of the system operation. Typically, the pre-condition specifies the properties of the system state that need to be checked when system operation is to be executed, and the postcondition defines the possible changes that the execution of the system operation is to realize.
Input of InitialGPT — Prompt Template
A good prompt template approach is the key to data generation, which can effectively prompt the large language model to generate data so as to better utilize the performance of the large model.
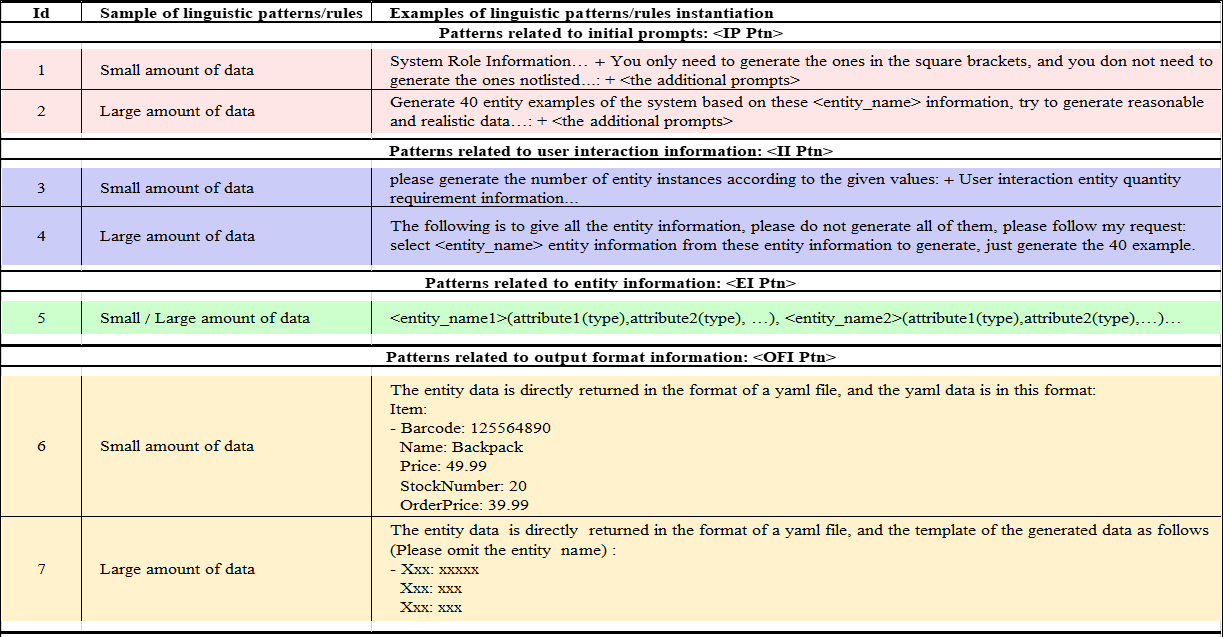
Since LLMs has the limitation of data response time and length for the api usage, we have designed two sets of templates for LLMs, which are used for generating general amount of data and large amount of data respectively.
Prompt Template
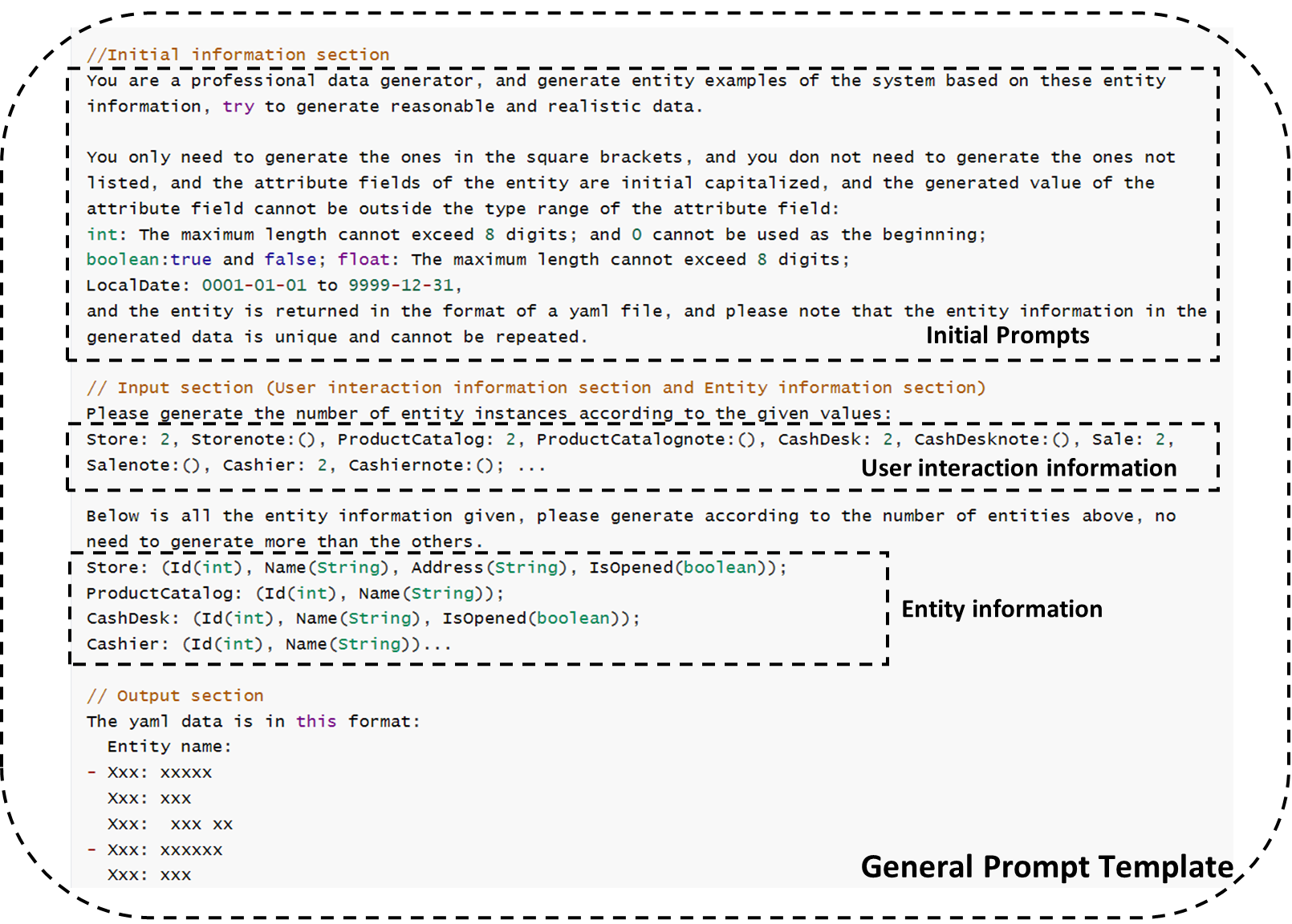
We have designed a corresponding prompt generation template as shown in the figure:
General Prompt Template
The general prompt template consists of three main components. The Initial Information Prompt is a well-tested general prompt, the Input section consists of user interaction information and domain entity information automatically generated by the requirements model, and the Output section specifies the format of the output data.
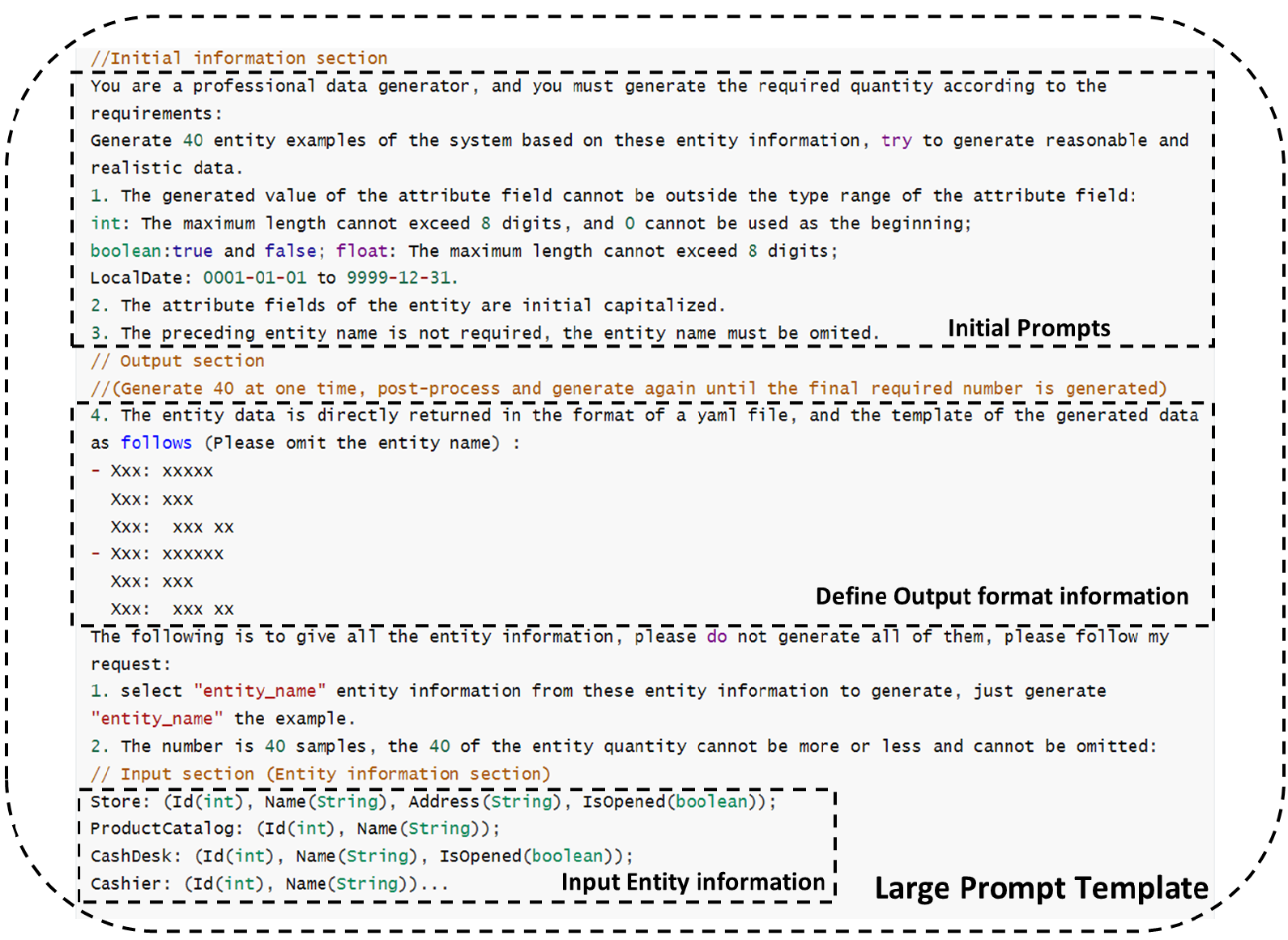
Large Prompt Template
The Large Data Amount Prompt Template is similar to the General Prompt Template, but is generated for a single entity, 40 at one time, and post-processed until the final required number is fully generated.
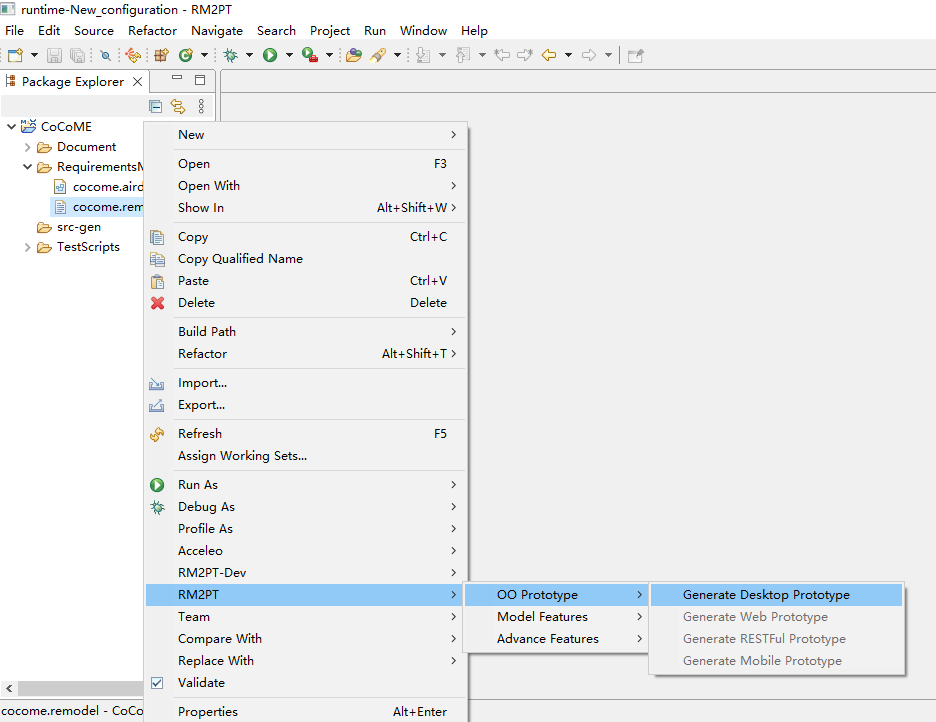
1) Generate a prototype from the requirement model
After you import a requirements model, first, we use the RM2PT to generate a prototype from the requirements model by right click on cocome.remodel -> RM2PT-> OO Prototype-> ` Generate Desktop Prototype`
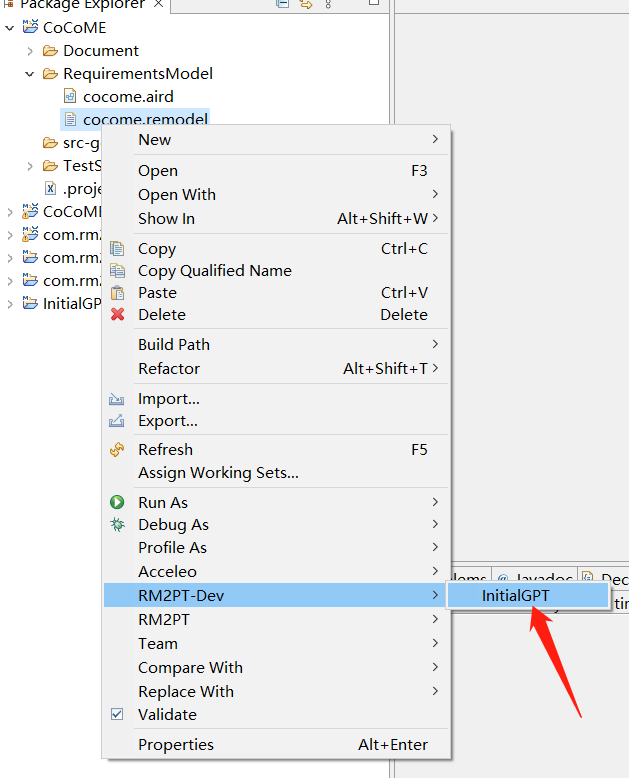
2) Run the InitialGPT tool to refactor and enhance the prototype
after you generate a prototype, we use the InitialGPT to refactor the prototype from the requirements model by right click on cocome.remodel -> RM2PT-dev-> InitialGPT, and update the project.
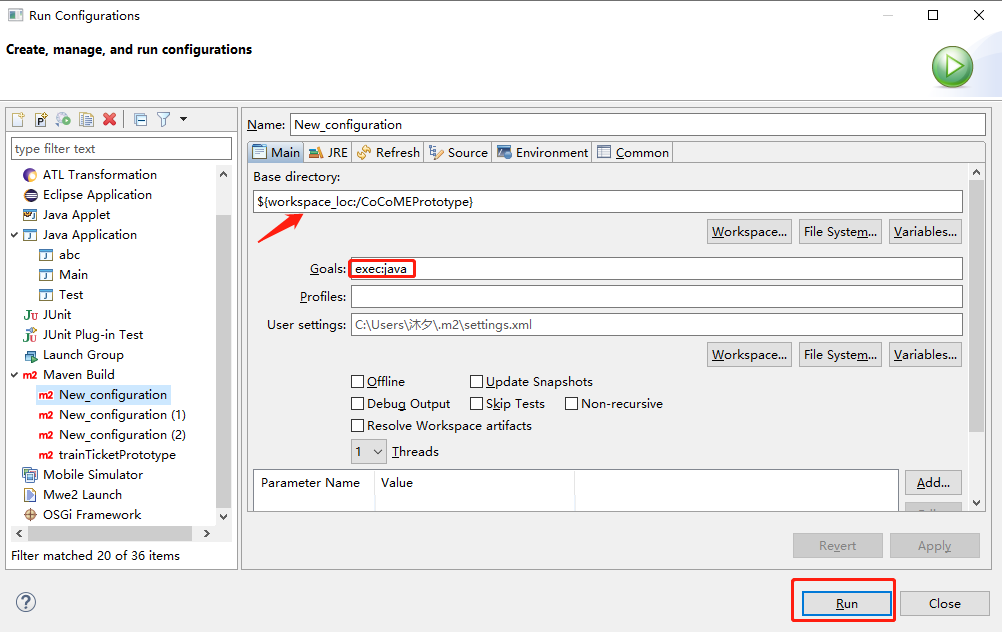
3) The third step is to run the refactored prototype
Run the refactored prototype to validate the requirements by right click on COCOMEPrototype -> pom.xml-> run-> maven build
.
4) Generate the initial data to validate the requirements.
The Output of InitialGPT
After automatically refactoring and enhancing the generated prototype by the tool InitialGPT, the enhanced prototype contains two advantages as follows:
-
Automatic initial data generation of prototypes. The enhanced prototypes can automatically generate large amounts of prototype initial data for requirements validation via a large language model.
-
Automatic Data Prompts Generation for large language models. A method is proposed to automatically generate prompts for large language models based on the requirement model, aiming to prompt GPT-3.5 to generate more compliant, reasonable, and effective data that satisfies the requirements.
-
Automated evaluation of generated data. To facilitate users in quickly understanding data quality, we have designed an automatic evaluation feature based on specific metrics.
For the CoCoME example
In the system status, Click on the initial data generation button and in the data generation screen
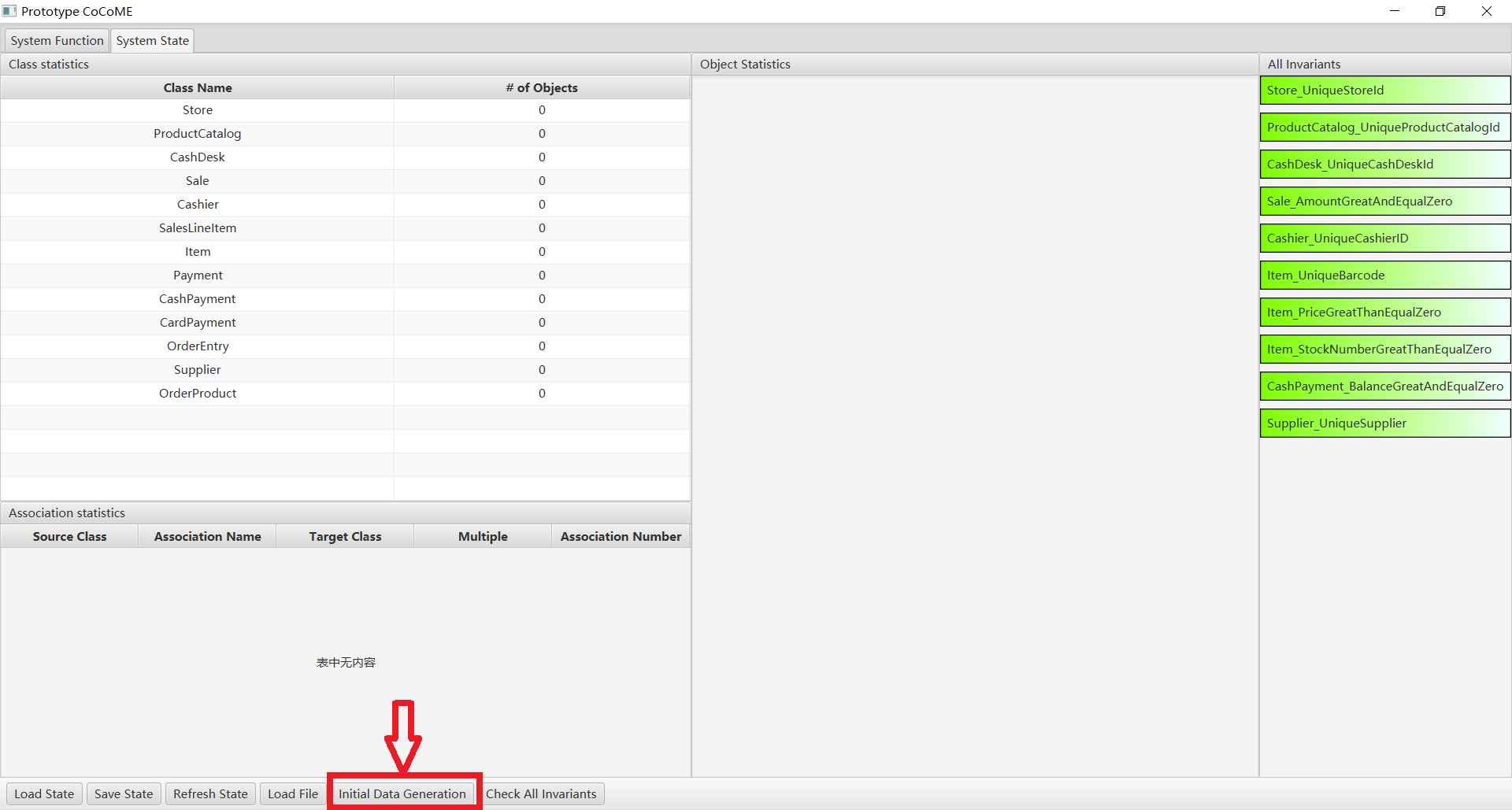
- The first step is to select a model. The current models used are gpt-4o, gpt-4 and gpt-3.5-turbo; more large language models will be added later.
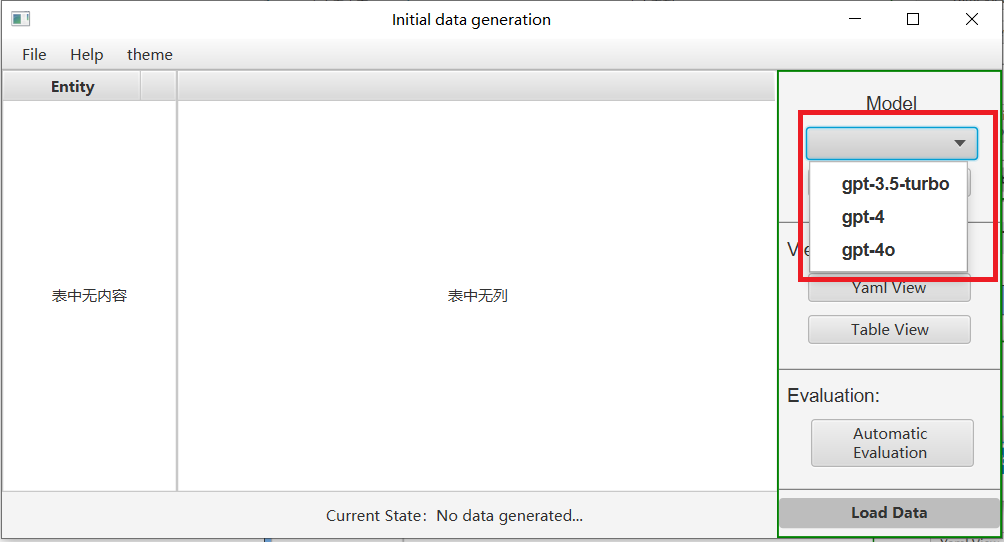
-
Click on Generate Settings and then choose whether to use a proxy on the pop-up page. If you do, please delete “no” and fill in your own proxy port, then fill in your openai key.
here you can set the number of entities we want to generate for each entity. Also, you can add as many prompts as you want to the note box.
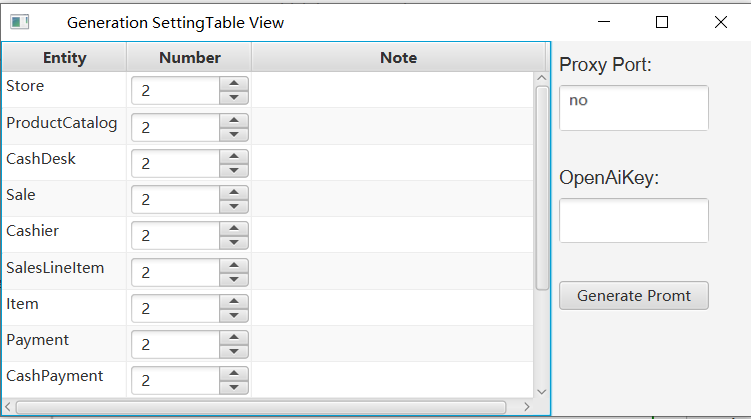
-
After the settings have been input, click on the Generate Prompt button and Prompt will be generated automatically. If you are not satisfied with the generated prompt template, you can further modify it.
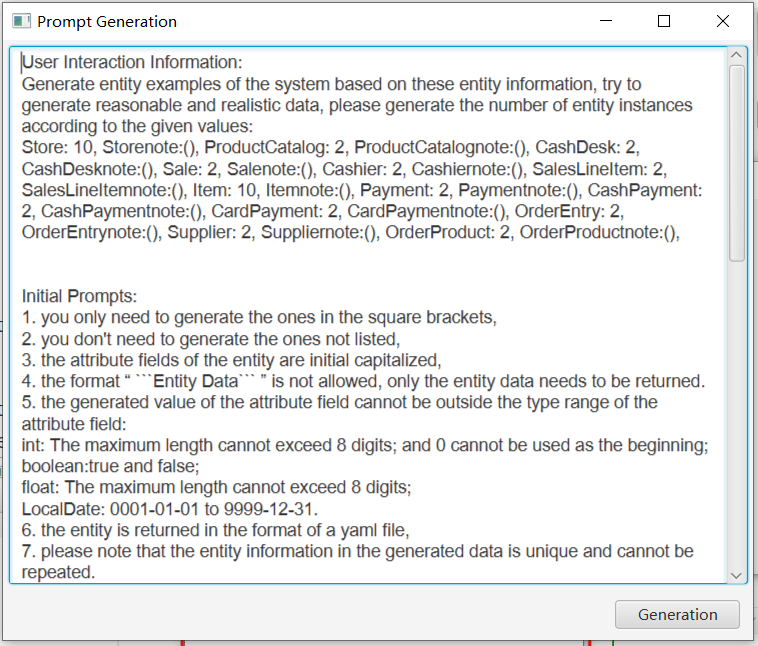
-
Then, click the “Generation” button. Here, you can see the time corresponding to the number of generated entities we have tested.
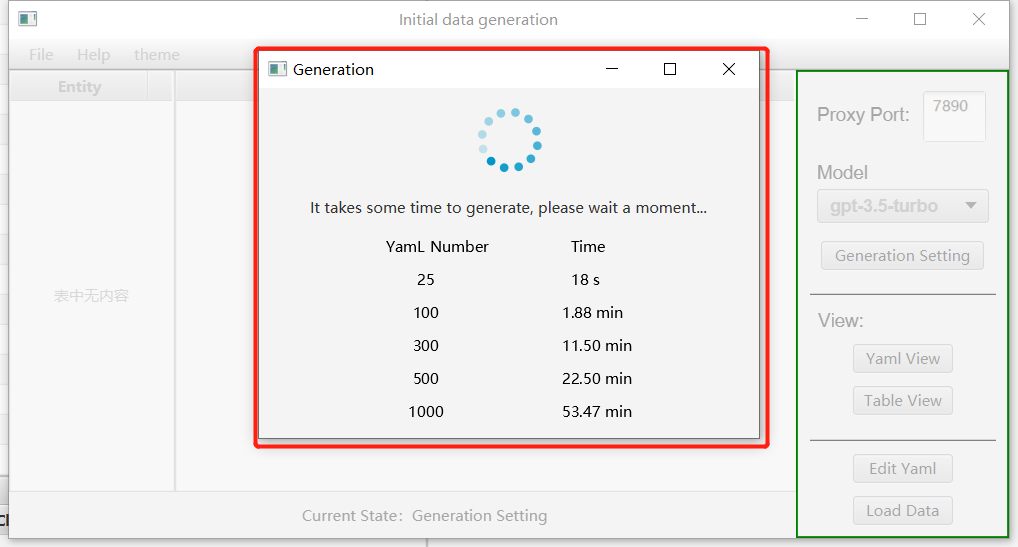
-
After successful generation, you can view the generated entities in the table view or yaml view, and you can also modify them to better match your requirements.
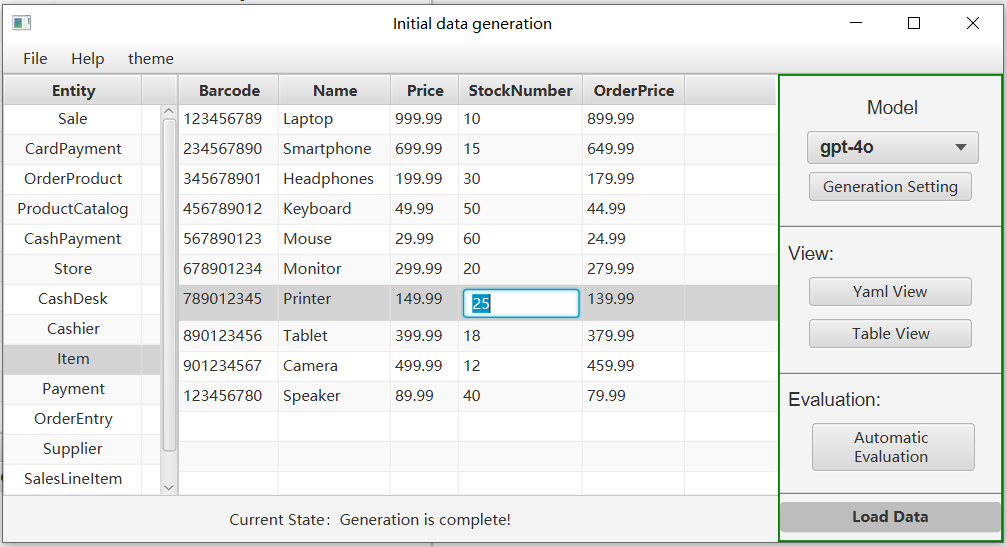
-
To facilitate users in quickly understanding data quality, we have designed an automatic evaluation feature based on specific metrics. You can click the “Automatic Evaluation” button to view the generated data on the panel. To start the evaluation, click the “Evaluation” button on the right.
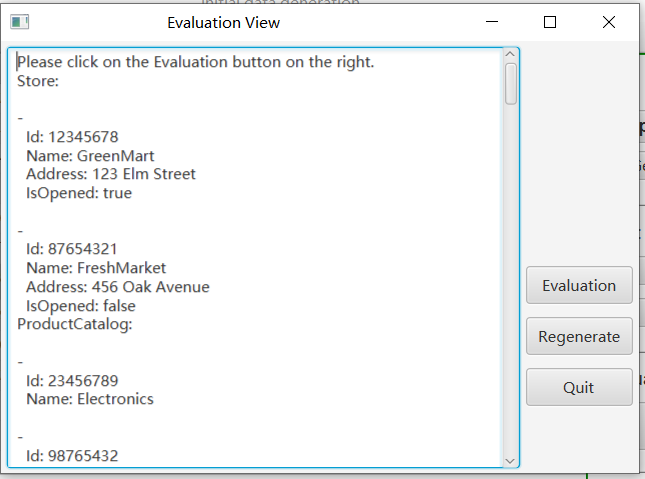
- Until completion of the evaluation, the evaluation results will be displayed on the panel.
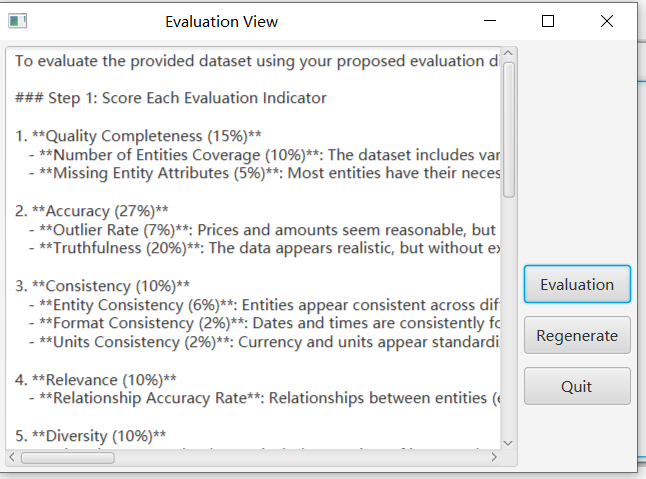
- If you are dissatisfied with the data quality, you may click the “Regenerate” button on the right. Once the data is regenerated, it can be viewed in the table.
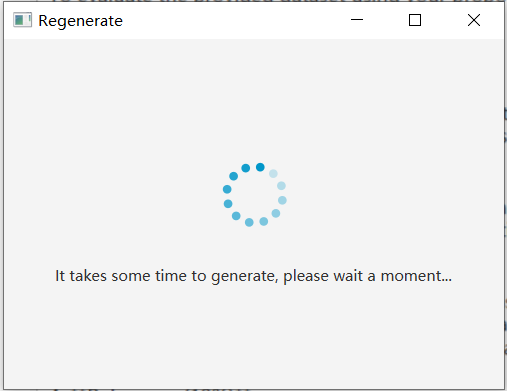
-
Finally, click on the “load data” button to import the initial data into the prototype.
- At the same time, the generated data is saved, and you can click on the Load File button to load the file directly next time without having to generate it again.
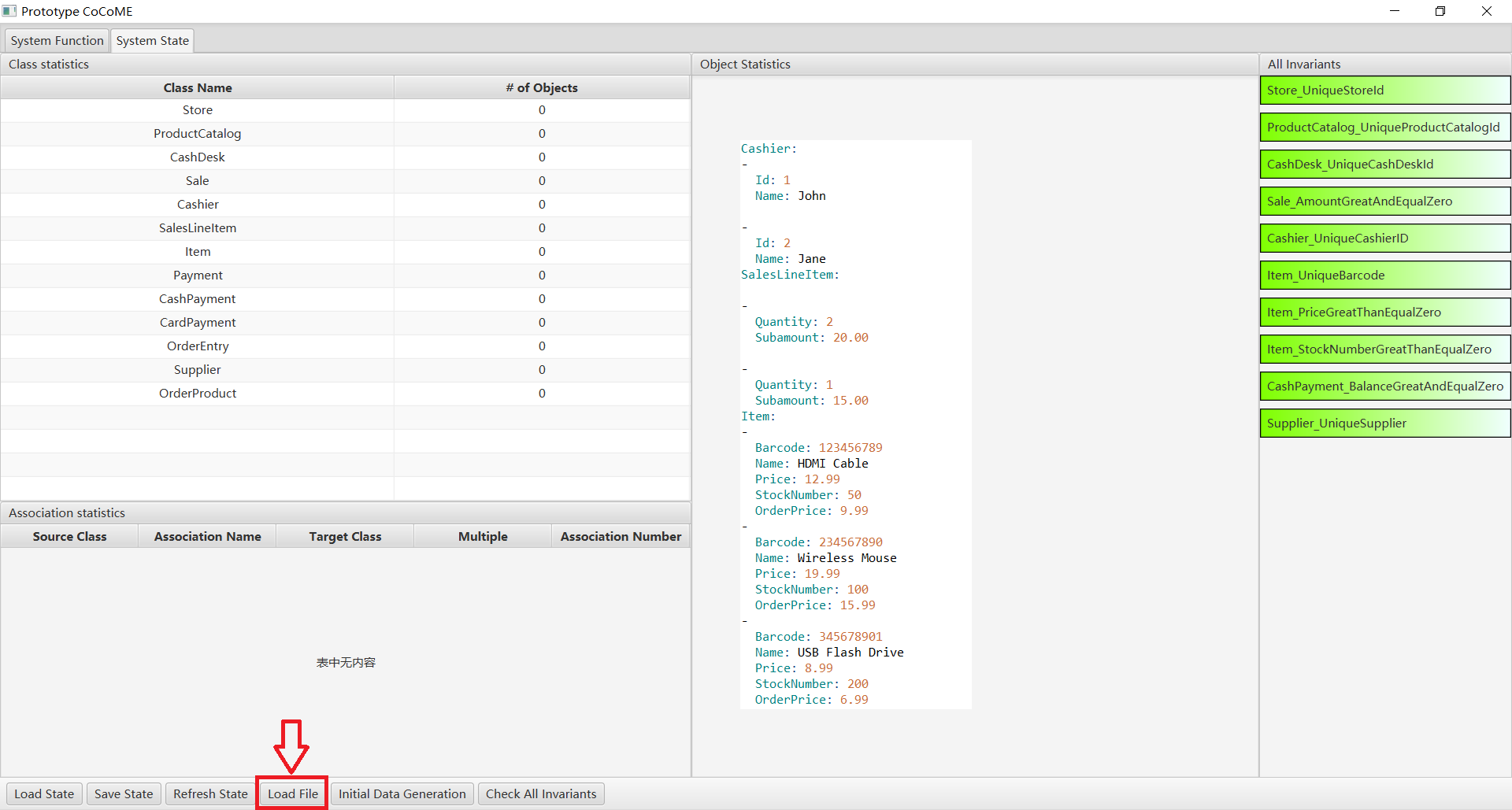
For more details, please see CaseStudies.
InitialGPT Evalution
Case Studies
In this section, we first present the case studies and then show the evaluation results based on the case studies.
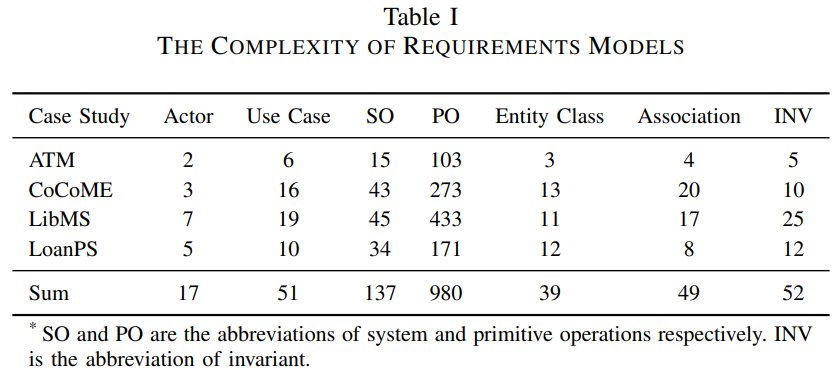
This paragraph discusses the reuse of four case studies to demonstrate the validity and functionality of InitialGPT. The case studies include systems that are widely used in daily life, namely a supermarket system (CoCoME), a library management system (LibMS), an automated teller machine (ATM) and a loan processing system (LoanPS). More details of the requirements models can be found at GitHub https://github.com/RM2PT/CaseStudies.
The complexity of these requirement models is shown in Table 1. InitialGPT’s experimental settings are 2.8GHz Intel Core i5, 16GB DDR3, JDK 11 (JDK 11 has been embedded directly into RM2PT). The large model is tested using the api of gpt-4o,gpt-4 and gpt-3.5-turbo. We have a concise training on utilizing CASE tools for requirements validation.
Evaluation Results
In this section, we first present the case studies and then show the evaluation indicators with evaluation results based on the case studies.
Efficiency Experments:
InitialGPT can refactor the prototype generated by RM2PT in combination with gpt to automatically generate the initial data. In order to assess effectiveness, we conducte a comparison between two versions:
(1) The prototype generated by RM2PT tool and (2) The improved prototype that refactoring by InitialGPT.
The experiments involve validating requirements through the generation of initial data using InitialGPT or manual writing of initial data. The results of the experiments are shown in Table II.
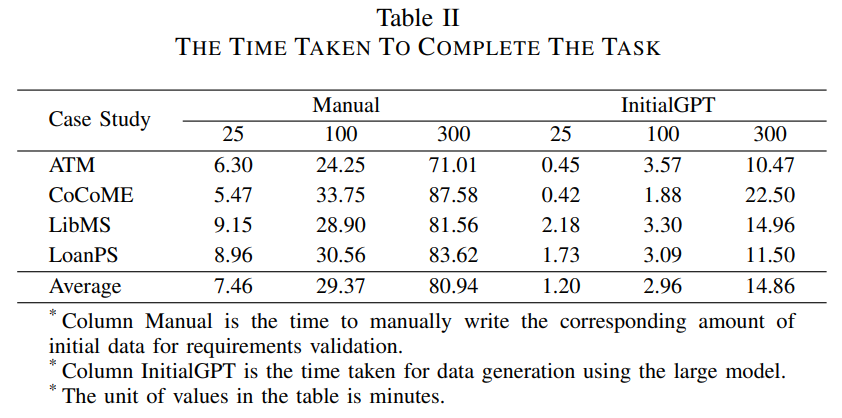
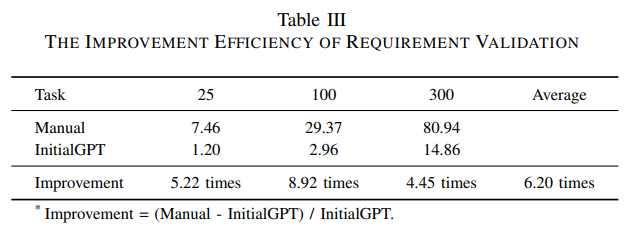
We calculate the time efficiency of using the prototype for requirements validation. As shown in Table 3 on average, it takes a developer 29.37 minutes to write 100 initial entities data, while ChatGPT takes only 2.96 minutes to automatically generate, and the enhanced prototype is able to improve the efficiency of requirements validation by 6x times **over a manually written prototype, and **the more initial data required, the more time is saved.
Quality Evaluation
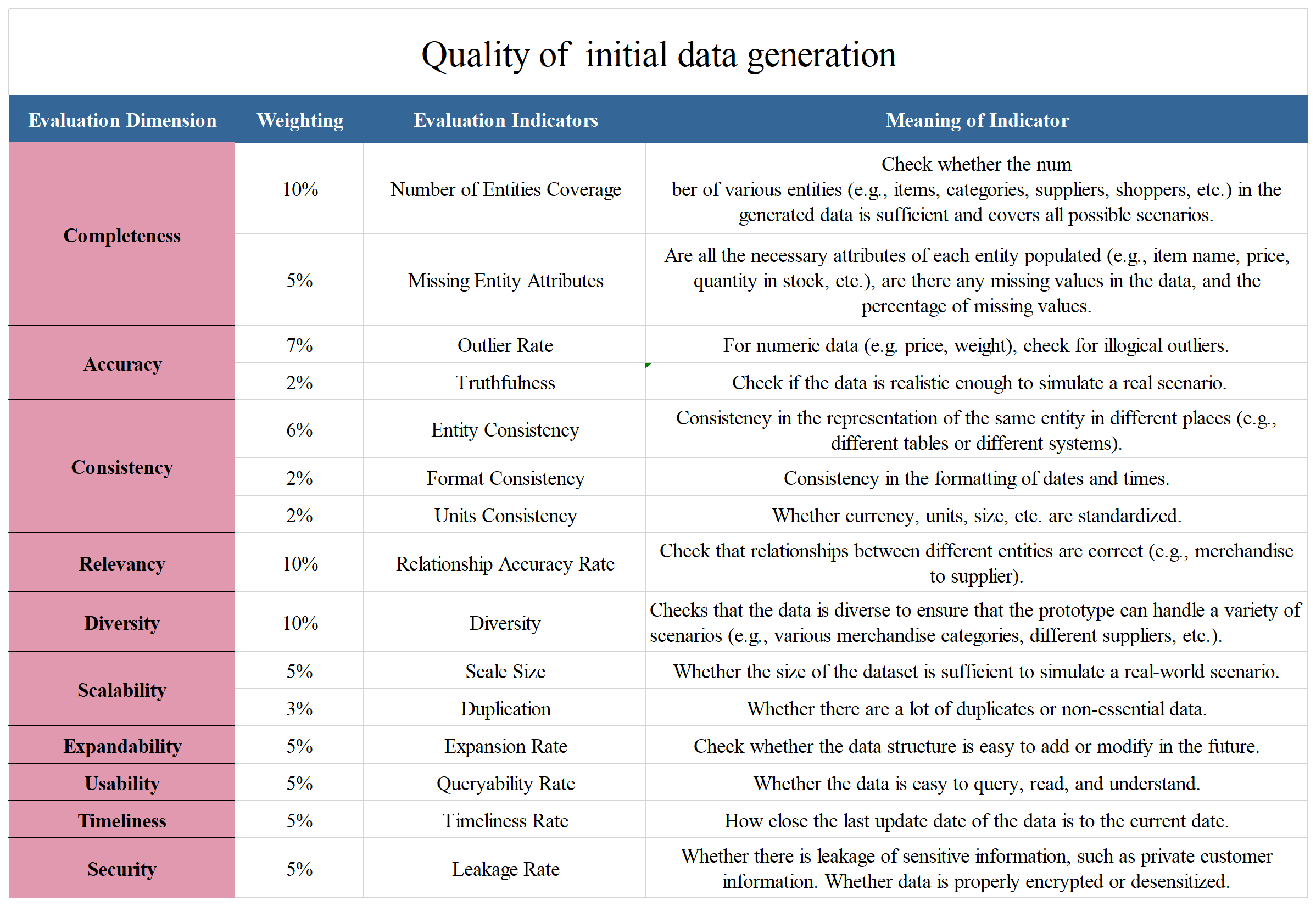
At the same time, we also evaluate the quality of GPT-generated data. For the evaluation of data quality, we propose 10 evaluation dimensions with 15 evaluation indicators.
Evaluation indicators for data quality
The detailed evaluation dimensions and evaluation indicators are shown in the figure:
Evaluation Rule for data quality
The evaluation rule is a 5-point scale, where the score of each indicator is calculated and then the total score is calculated based on the corresponding weights.
The evaluation rule is a 5-point scale, using the “Number of Entities Coverage” as an example. 5 points: The data cover all entities and there are enough of each. 4 points: The data covers most entities, but the number of entities is sufficient. 3 points: The data covers most of the entities, but there are some omissions in the number of entities generated. 2 points: The data covers a basic range of entities and there are omissions in the number of entities generated. 1 point: The data covers very few entities and the number of entities generated is small. 0 points: The data does not cover any entities or the data is not available at all. From high to low, a score of 5 indicates that the data fully meets the requirements of the evaluation indicators, a score of 1 indicates that the data rarely meets the requirements of the evaluation indicators, and a score of 0 indicates that the data does not meet the requirements of the evaluation indicators at all and is not available.
Results of data quality evaluation
We conducted three experiments as shown in Table IV.
Table IV show that the quality of data generated by GPT-4 is better than GPT-3.5-turbo, which is basically similar to the quality of manually written data.